
 The increasing overlap, and potentially inextricable intertwining of recruitment and marketing has been a central theme in the HR industry, the subject of a prodigal amount of product marketing, ‘thought leadership’ content and corporate copy.
The increasing overlap, and potentially inextricable intertwining of recruitment and marketing has been a central theme in the HR industry, the subject of a prodigal amount of product marketing, ‘thought leadership’ content and corporate copy.
The confluence of recruiting and marketing has, in fact, become a central focus in competing for top talent, with concepts like employer branding, SEO, segmented “talent networks” and e-mail campaigns moving from the margins of recruiting to the mainstream of how companies find, attract and engage candidates.
Not so, says Andrew McKay, CTO & Co-Founder of KonaSearch, which provides a “single, universal search application within Salesforce that searches all Salesforce data along with content from external sources,” including an integration with Jobscience, its primary foray into the recruiting technology market. In fact, McKay said in a recent interview with Recruiting Tools, recruiting actually has little in common with marketing from a strategic or systems perspective, instead aligning much more closely with customer service and support as a reactive, highly tactical and performance-based function.
RecruitingTools recently spoke with McKay, a technology industry veteran widely considered one of the world’s top experts in enterprise search (and, coincidentally, author of the Wiley book Enterprise Search for Dummies) about the future of enterprise search, systems and sourcing, and some big ideas about big data and why Boolean continues to survive – and thrive – in the new world of search.
 We’re also hearing a lot about Big Data. From your point of view, what, exactly, does big data mean and how should businesses approach tackling the massive amount of information available to today?
We’re also hearing a lot about Big Data. From your point of view, what, exactly, does big data mean and how should businesses approach tackling the massive amount of information available to today?
Andrew McKay, CTO & Co-Founder – KonaSearch: I’m going to be truly lazy here and simply quote Wikipedia: “Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.” This is actually a fairly accurate definition. I would add to the definition the presence of both structured data (database records) and unstructured content (documents), both derived from sources that are internal (operational data, ERP, CRM, KM, etc.) and external (social data, public information, etc.). I would also include an indication of what the data is used for, i.e. discovery, analysis, prediction, etc.: quantitative data mining and analysis for structured data and qualitative content mining and analysis for unstructured data.
The key distinguisher, however, is that it is BIG – too big for conventional (read: traditional) technologies. Big means 10s or 100s of terabytes and even petabytes, and it is disrupting the most stalwart technologies: the SQL database and data warehouse, even storage media. Our conversation here (for Kona), though, is about retrieval and analysis.
Some vendors emphasize that added insight derives from the interaction of data and content technologies, insight that leads to true predictive analytics. The argument goes like this: data analytics answers “who, what, where and when”; content analytics answers “why”. Together you get “active intelligence”, or “actionable information”, two common terms from the Big Data lexicon. There is truth to this, if for no other reason that for the first time, analysis is covering ALL information from the organization, not just the structured or unstructured skew from BI/data mining or search services deployed separately. An aside: I’m always trying to explain what I do to my mother. I hit on this analogy: search is the left eye view, BI is the right eye view. Only when they’re used together do you get depth perception. Lame, but it works.
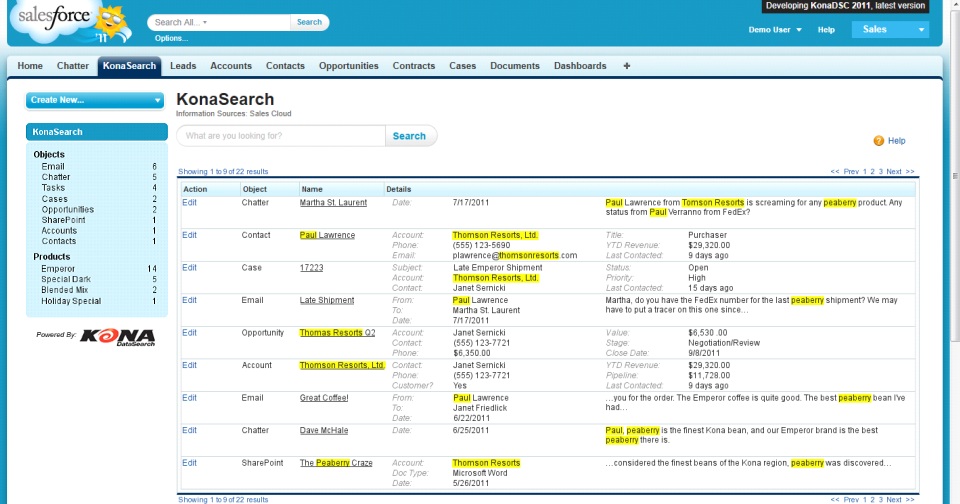 What do you see as being some of the major trends in search, specifically the larger trend of federated or universal search that we’re seeing?
What do you see as being some of the major trends in search, specifically the larger trend of federated or universal search that we’re seeing?
I have to qualify your definition of “search” as an industry by separating web, or public, search (Google, Bing, Yahoo, etc.) from enterprise search, a market that has been around since the 1980s and 1990s with Thunderstone, Fulcrum, Alta-Vista, etc.
Enterprise search went through a consolidation phase some years ago when all the largest players sold to major concerns (e.g. Fast Search & Transfer to Microsoft, Autonomy to HP, Endeca to Oracle). In this time, we saw the rise of Lucene and Solr (and later Elasticsearch) in the Open Source community and a new generation of search engines built around them (e.g. Attivio: full disclosure, I’m a co-founder).
What made them different than previous engines? They were tackling Big Data before “Big Data” was a phrase, essentially the problem of bridging structured data (databases) and unstructured content (documents) in extreme volumes. Graph processing (e.g. MapReduce) was a key factor in opening up analytics and soon became part of the mix (by the way, before Facebook introduced its graph search release). Earlier, Enterprise search had started specializing (e.g. legal discovery, Q&A systems for call centers, voice of the customer, social media and sentiment analysis) and this accelerated.
Key trends today are:
- Simplicity – Ease of implementation, tuning, and management. Enterprise search has suffered from ignoring “mere mortals”. No longer. Organizations today have much less tolerance for months of configuration and tuning by highly paid search experts. Thank Google (rightly) for “it just works”.
- Centralization – One logically integrated search engine for the entire organization across multiple, heterogeneous structured and unstructured sources. “Logically” means that while it appears as one index, it is physically distributed to where the data is. This is not a new concept of course, but perhaps the first time it is more than a holy grail. Recall the similarity to the original goals of the data warehouse.
- Real-time analytics – Analytics on demand and in real time. Also, embraces integration of both data mining and text mining capabilities. BI and search together. The term “360-degree view” is returning (although it was way over-used the first time).
- And of course, search in the cloud as a service – New vendors are appearing rapidly. Amazon provides a search service as part of their EC2 suite, for instance.
Note the absence of “federated search”. It really depends on what you mean by it. The formal definition, courtesy of the search industry, is posting a search query to the search engine of a foreign system, getting its results as a simple ordered list (no relevancy scores, facets, metadata, etc.), and listing the results separately along with results from other sources. You can’t integrate the results of course because whose #1 result is really #1? And there are no facets or other advanced search features.
By this definition federated search has been around since the 90s and was generally considered the lowest common denominator of search – a quick fix solution for responding to the need for heterogeneous environments. In fact, federated search used to be a separate sub-market of enterprise search, but it disappeared due to lack of demand.
Now, if your definition of federated search is more about true search integration (“integrated search”), where data from all the sources is indexed in one location so that results can be returned with one relevancy context, then it has much more relevance to our discussion. However, even this is not what I would call a major trend as it has been a tenet of enterprise search for a long time. The trend, if any, is properly including structured data into the mix.
This is a big one. Is Boolean search dead? With tools like Konasearch, do you think that sourcing has a future as a dedicated function?
No. Autonomy said this 15 years ago (Autonomy is based on Bayesian logic), and it was wrong then as well. It still forms the basis of pragmatic search logic. And its close proximity to SQL means that it can embrace structured data easier without compromising the cardinal relationship of the RDBMS. But, this does not mean users should be entering Boolean searches, despite the fact that we see Boolean searches entered all the time by our recruiting customers.
The ubiquitous search bar today may be fine for web search but the enterprise demands more context from the user and data. Think of the search bar as the search UI of last resort. As search becomes more integrated into the fabric of the application, information appears in context from the search engine because the context at the time can generate the search query automatically. Example: matching candidates to job orders and job orders to candidates. The search uses the profile of the context record as the basis for the search query. The search query, however, is still Boolean.
Can other machine-learning technologies be included, like Bayesian logic? Sure, but carefully. We find interesting the continued resistance to auto-improvement of search results, where the same search can return different results. It’s generally viewed as chaos – rightly or wrongly, people equate consistency with accuracy and trust.
As a high-tech startup, what’s your philosophy on recruiting talent? What are you doing internally to attract and retain skilled developers and tech professionals, and what are some of the major myths or misconceptions around tech hiring or recruiting?
Not sure if this rises to a philosophy, but we try to use our network wherever possible. It’s always safer to hire who you know and trust then to reach out anonymously and start fishing. Failing this, we reach out to the recruiters we have used in the past and trust; consider this the next level of indirection. Once a successful candidate is found, we tend not to hire immediately but to 1099 first. Will this work for everyone? No, but where it does (e.g. engineering) it greatly reduces risk. Firing someone is so painful and expensive to both parties.
As for retention of technical people, well, we are still a very small company. But having built teams in the past numerous times, in the end it’s not the money, it’s the quality of the job and the challenge. That doesn’t mean you don’t pay them well – everyone does, so it’s a right to play. The decision will be made on whether or not the company and its products are technically credible (ignore market viability for the moment), and the management staff are technically and operationally credible. Nothing deflates an engineer more than working for an idiot or having to build something that has no challenge or relevancy.
Myth 1: Engineers do not understand and do not care about, or are indifferent to, the health of the company – that’s not true anymore.
Myth 2: Engineers do not care about Sales or about how the product is used – they care, they just sometimes don’t accept why people buy things and why they are attracted to certain products.
Myth 3: Engineers are not attracted to money – nonsense, it’s a right to play.
Myth 4: Give them a black box to solve and they are happy – today’s engineers want to understand the bigger picture and feel they are involved somehow in its creation.
Myth 5: Hiring older engineers means you have to un-train them first – experience of repeated patterns and avoiding pitfalls trumps resistance to change.
Myth 6: Engineers are not career-oriented – self-explanatory: everyone wants a growth path.
I’m sure there are more if I keep going.
For more Q&A with Andrew McKay, check out the full post from Recruiting Tools.
By Matt Charney
Matt serves as Chief Content Officer and Global Thought Leadership Head for Allegis Global Solutions and is a partner for RecruitingDaily the industry leading online publication for Recruiting and HR Tech. With a unique background that includes HR, blogging and social media, Matt Charney is a key influencer in recruiting and a self-described “kick-butt marketing and communications professional.”
Recruit Smarter
Weekly news and industry insights delivered straight to your inbox.



